
When AI agents interact with live systems and sensitive data, safety can’t rely on a single model or moderation filter. True protection comes from layered guardrails: a structured stack spanning model-level safety, structured tool execution, policy-based authorization, and secure architectural topology for AI agents. Together, these layers can make actionability predictable and enforceable via deterministic control planes, despite probabilistic AI generation.
Let’s take a look at the four interdependent layers of enterprise AI guardrails for agents, showing how each reinforces the others to create consistent, compliant, and controlled behavior.
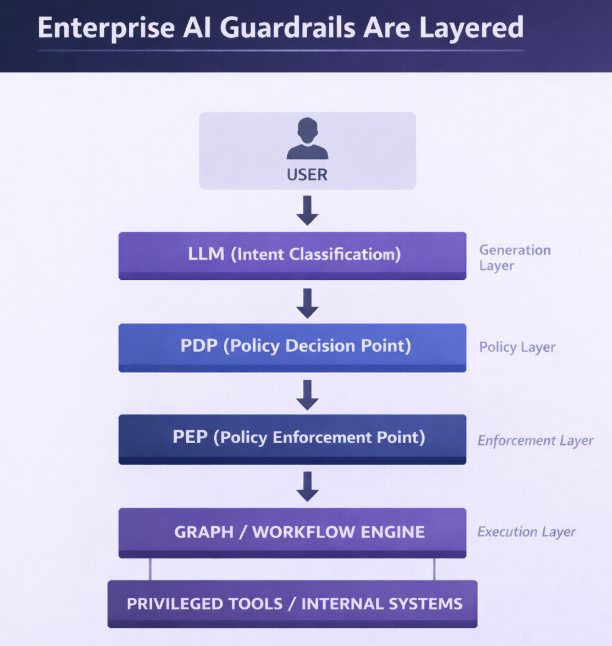
When a user sends a prompt, the LLM may interpret intent and propose a tool call, but it does not execute actions directly. Any proposed action must pass through a deterministic authorization layer: a Policy Decision Point (PDP) evaluates whether the action is allowed based on identity, roles, and contextual attributes, and a Policy Enforcement Point (PEP) either executes or blocks the request.
Layer 1: Model-Level Safety
Major AI model providers such as OpenAI, Anthropic, and Google include built-in safeguards like content moderation, harmful instruction filtering, abuse detection, and output risk classification. These operate strictly at the generation layer.
They reduce harmful or disallowed outputs. However, they do not understand your tenant model, enforce billing permissions, apply escalation policies, or enforce access control rules such as Role Based Access Control (RBAC). And even if they understand your policies, they cannot guarantee that privileged internal tools won’t be executed unless your application enforces authorization.
Model-level guardrails are global safety constraints, and are important. But they are not enough. Enterprise-grade agent safety requires additional layers that contain and control actions beyond text generation.
Layer 2: Tool Interface Integrity (Structured Execution & Validation)
Modern LLM APIs support structured tool calling through JSON schemas, function definitions, and typed arguments. This defines a strict contract between the agent and the system.
At this layer, only explicitly registered tools can be proposed, and all parameters are validated against schema and semantic constraints. Structured execution ensures that tool calls are well-formed, constrained to known capabilities, and syntactically and semantically valid.
Layer 2 defines the capability surface and guarantees input integrity. It does not determine whether an action is permitted, only whether it is structurally valid.
Layer 3: Policy Enforcement
Enterprise systems have long separated decision from execution. Two concepts from classical access control formalize this pattern:
- A Policy Decision Point (PDP) evaluates whether an action is allowed based on identity, roles, and attributes.
- A Policy Enforcement Point (PEP) intercepts the request and enforces that decision by allowing execution or blocking it.
This approach underlies RBAC (see above), attribute-based access control (ABAC), and zero-trust security models. Applied to AI agents, the LLM may classify intent, e.g., escalate, refund, delete, but it does not grant privilege. The PDP evaluates authorization using deterministic policy rules, and the PEP enforces the result.
Authority must come from verifiable signals such as signed JWT claims and explicit policy definitions. In practice, this typically means two overlapping control mechanisms:
- Role-Based Access Control, where permissions are tied to roles
- Attribute-Based Access Control, where decisions depend on contextual attributes such as region, transaction limits, or customer tier
The result is that every tool call from an AI agent passes through deterministic authorization before execution, not probabilistic prompt behavior.
Layer 4: Architectural Topology
Architecture itself can and should act as a security boundary for AI agents. In graph-based agent systems, escalation and privileged tool execution follow defined routes. If no route exists for a caller, execution cannot occur. Conditional edges encode policy checks, and human approval nodes create deliberate choke points for high-impact actions.
This design turns system structure into an enforcement mechanism: deny-by-default at the topology level. Agent-centric frameworks that allow tools unless expressly blocked reverse this principle and increase risk exposure by default.
When combined with least-privilege credentials and network isolation, topology reduces blast radius and ensures agents can only traverse explicitly defined execution paths.
Authorization alone is not sufficient for production systems. Enterprise deployments must also enforce business invariants, rate limits, quotas, and post-condition validation. Tool services should operate under least-privilege credentials with strict network segmentation, and agent runtimes should be isolated from execution services to prevent privilege escalation or cross-tenant leakage.
Why AI Guardrail Layers Must Work Together
Each layer secures only part of the agent’s behavior; none can stand alone:
- Model safety safeguards content, not actions.
- Structured execution organizes requests, not privileges.
- Policy enforcement ensures authorization, but only within defined architecture.
- Topology enforces the physical and logical boundary, but relies on upstream validation.
Together, these layers transform probabilistic AI reasoning into deterministic enterprise behavior—a closed loop of generation, validation, decision, and containment for AI agents.
In regulated domains like healthcare, fintech, and telecom, where AI agents access sensitive data and orchestrate real operations, these layered guardrails are essential. Relying solely on prompting or moderation is an architectural gamble. LLMs generate. Systems enforce. Guardrails are not a single feature; they are a layered design decision.
Disciplined Architecture Is the Real Guardrail
There’s no single feature or vendor setting that guarantees safe, compliant AI agents. Enterprise security comes from disciplined architecture: combining model-level safety, structured execution, policy-based authorization, and architectural topology into one cohesive framework.
Platforms like Amazon Bedrock provide governance and guardrails at the model boundary—content filtering, topic controls, and PII protection—integrated with IAM and the broader AWS ecosystem. These are powerful components of a safe agent stack, but organizational policies such as tenant isolation, refund thresholds, and escalation hierarchies must still be explicitly designed into your architecture.
With AgilityFeat’s AI Integration Services, we design and deploy enterprise AI agents where authorization, policy enforcement, and execution boundaries are layered by design, not added after the fact. We treat policy enforcement as a first-class architectural concern.
Ready to build enterprise AI agents that are safe by design? Schedule a strategy call.
—————————————————————————————————————————
Further reading:
- Voice AI for Fintech, Healthcare, and Regulated Industries: Architecture for Production Systems
- Deploying AI Agents in Production with AWS
- Building Investable AI Startups: The Value of Nearshore Development Partners
- How to Hire LLM Engineers: Why Latin America Solves the AI Talent Crisis
- Building a Voice AI Agent with Policy Guardrails Using Twilio, Pipecat, and LangGraph
- Building Layered AI Customer Service Architectures: When Rules, SLMs, and LLMs Work Together








