Last month the QANews newsletter by Sogeti was released, and I was pleased to have an article I wrote on Agile Database Testing published in it. I’ve reproduced the article below, and you can also see the original article here.
Agile Database Testing
Testing database changes
Testing is rarely easy, and is more often thankless. This is particularly true when testing a heavily database driven application. Those responsible for testing are asked to test large sets of functionality in a short period of time, and they have the final “sign off” before an application can be deployed.
When an application is heavily dependent on a database, there is extra stress in testing just before deployment. The tester has to worry about questions like:
- Am I testing against the right version of the database code (ie, stored procedures, views, tables, etc)?
- Are any errors due to software bugs, or a configuration issue?
- Am I testing against the right data to uncover bugs?
- How can I recreate this problem in the development environment?
How can the testing team be more confident when testing large data sets and large database changes just before deployment? Adoption of agile database development and testing techniques can create this confidence, but only if they are adopted correctly.
What agile brings to the table
Agile methodologies like Scrum and Kanban have two important impacts on a testing team:
- Shorter iterations of development (2-3 weeks) mean more frequent testing cycles, ideally on a more limited set of features.
- XP practices like Test Driven Development (TDD) mean that developers should have already tested and verified much of their code before sending it to a testing team.
Both of these impacts can be very beneficial to testing teams. The shorter development iterations (or “sprints”) mean that the testing team has less new functionality to test at once. Ideally you are only testing the new features being developed in that iteration.
Full regression testing is still good practice, but the shortened release cycle will not allow you to fully regression test the system manually. You will need to invest the time to automate regression testing so that you can focus on testing the new functionality.
However, you don’t have to do the testing alone anymore. TDD means the developers should have already written many automated tests for you, and these automated tests should be running on a continuous integration server every time code is checked in.
How agile complicates traditional testing
In many traditional projects, the developers work on chunks of functionality for weeks at a time without integrating their code with each other. Then they go through an integration phase, where they spend a lot of time getting their code to work together, and only then do they turn it over to testing.
In a way this traditional integration cycle is convenient for testers. You only have to do your testing once, and you don’t have to start until developers get through the pain of integration.
In agile teams however, the developers should be integrating code daily. Each day they all check their code into a repository, and a continuous integration server grabs that code and runs their automated tests against it. Instead of a painful integration phase where developers spend days trying to reconcile their separate changes, the merging and integration are done daily in small chunks that are more easily accomplished.
This means that a testing team must be ready to constantly test the system, following right behind the development team. Regression testing needs to be automated and efficient so that testers can focus on exploratory testing each day.
From a database perspective, the frequent changes by developers also mean frequent database changes. Table columns will be added and dropped as the database design evolves, and test data will need to be changed and repopulated easily to support the automated testing. These frequent database changes need to be easily applied to multiple environments so that the testing team can easily synch their test database with a particular version of the software being developed.
Agile Database Testing lifecycle
First, let’s consider the simpler scenario. Assume that your test database is already up to date and in synch with the software under test. How do automated tests manage their test data? Consider the following scenario where one test causes a problem in another test:
Figure 1: Dependent tests causes failure when the data changes
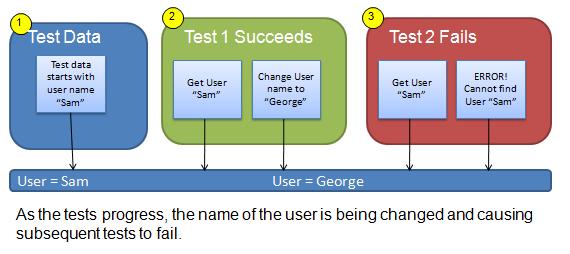
The way to handle this is by creating the test data you need for each test. While the terminology will change in different languages, the basic steps always follow the same concepts of Setup, Test, and Teardown.
Figure 2: Independent tests will pass since data changes are unique to the test
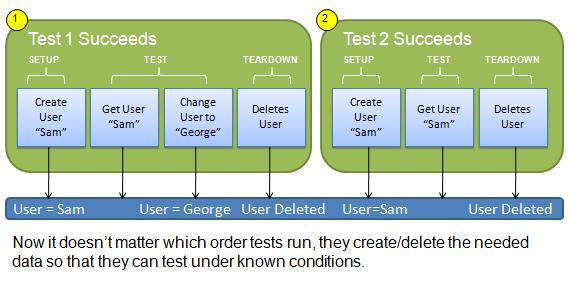
In this case, both tests will execute successfully because there is no data dependency between them. Following this pattern allows you to build tests that adhere to the FIRST properties: Fast, Isolated, Repeatable, Self-verifying, and Timely.
Agile Database Development lifecycle
Now that we understand how our tests are written against a changing data set, let’s consider how we keep our database in synch with the code we are testing. In a traditional testing environment this can be difficult, because it involves multiple people and likely time delays.
Figure 3: Database testing with multiple handoffs. Handoffs are indicated by the relay runners, and each can introduce an unknown delay of hours to the testing process.
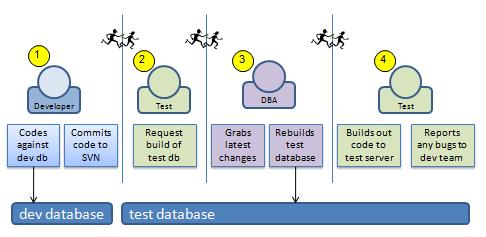
Instead, if the developer scripts out the database changes that are needed both to add their change and to remove their change, then we can automate this process using agile development tools and cut out some of the manual hand offs.
Figure 4: Database migrations can be run automatically using scripts written by the developers, which make it easy for the testing team to switch the database to a version which matches the software being deployed.
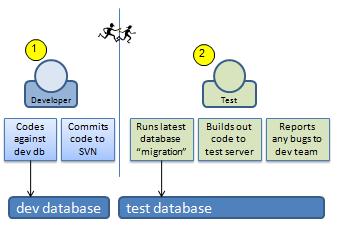
The terminology varies depending on the language you are using, but we’ll use the term “migrations”, which is most familiar to Ruby on Rails developers.
A migration is a simple script that the developer writes. This script has two parts:
1) Up migration: Makes the change needed for their new code
2) Down migration: Reverses the change needed if you are going back to the previous version
For example, if we write a migration that adds a new table, it might look like this:
____________________________
Version 1:
Up:
create table my_users (name varchar(100), username varchar(100))
Down:
drop table my_users
____________________________
After working with version 1 of the database for a while, we might realize that the my_users table needs to store birthday for each user. A migration for version 2 might look like:
____________________________
Version 2:
Up:
alter table my_users add birthday datetime
Down:
alter table my_users drop column birthday
____________________________
Note that in both cases, the down migration removes the changes added in the up migration. Ideally they should be mirror images of each other.
You can also use the migration scripts for populating table data that will consistent across all tests, and that will exist in your production system. For example, you might want to create a migration that populates a look up table of country names. But test data should be created and removed in the “setup” and “teardown” steps before and after each test, rather than in migrations.
Think of the migrations as the place you will write all database changes that ultimately go to production, and the setup/teardown as the place where you handle all database data specific to a particular test.
Tools that support Agile Database Testing
This may sound hard to implement, but fortunately there are a number of open source tools that support agile database development and testing.
If you use Ruby on Rails or Grails, then the concept of migrations and fixtures (the setup/teardown) is already built in for you.
For other platforms you can look into tools like dbunit and dbmaintain. Both are free open source tools with good examples and communities.
Challenges to adoption
Learning the tool sets that support these techniques can be a challenge to adoption, particularly for teams who have never done any agile database development before. For those teams, an outside coach may be beneficial to help the team see how they need to change their coding practices.
Most of the challenges you will face are process oriented, rather than technical. For example, if your team currently shares one development database across all developers, then you probably already know that it can be a pain for the development team when developers are making frequent database changes. But once you get up and running with agile database techniques, it will be easier for developers to each have and maintain their own database, and then their changes won’t immediately affect everyone else (though it is still important that they check in their database changes daily).
Environments with a very strict database security policy or build processes will also have some trouble adopting these techniques. However, this is an argument for loosening security policies for development environments, or automating build processes. The efficiency benefits of these techniques outweigh the initial work to support them.
Finally, you can see that these techniques will give developers more power than some database administrators are comfortable with. This is a reality of efficient development and cannot be avoided. For database administrators who are nervous about this, they will need to change their role to one of code reviewer and architect, rather than hands on script writing. Hopefully they will recognize this as a blessing that allows them to focus on other issues and not worry as much about day to day maintenance of development and testing environments.
Conclusion
Testing database driven applications is much easier when all you have to say is “Go run version 342 of the database, execute this automated test, and you’ll see what I mean.”
There are no concerns over what version of the database tables or procedures are being used, or what test data will recreate the problem. With a few simple commands and the right agile database driven techniques, you will be able to confidently and efficiently identify the source of bugs. Or at least easily recreate the environments to prove they exist.
About the author
Arin Sime is an Agile Coach with AgilityFeat. Arin is based in Virginia in the United States, but able to work internationally. He is a Certified Scrummaster and has spoken at several Agile conferences. Arin holds a Masters degree in Management of Information Technology from the University of Virginia’s McIntire School of Commerce. You can reach him at Arin@AgilityFeat.com or on twitter @ArinSime. He will be speaking at the upcoming XP2011 conference in Madrid on range estimation techniques in agile.
References
http://www.agiledata.org/
Excellent information and books by Scott Ambler
http://michaelbaylon.wordpress.com/2010/10/08/agile-database-development-101/
Provides an indepth overview of agile database development techniques
http://agileinaflash.blogspot.com/2009/02/first.html
An explanation of the FIRST properties of unit tests by Brett Schuchert and Tim Ottinger








